Newsletter για δράσεις Τεχνητής Νοημοσυνης
Οκτωβρίου και Νοεμβρίου 2024
Ενημέρωση του αποθετηρίου
Η εργασία που πραγματοποιήθηκε από την ομάδα glossAPI την τελευταία περίοδο φαίνεται στο commit history https://github.com/eellak/glossAPI/commits/master/ & https://github.com/eellak/glossAPI/issues .
Πεπραγμένα
Δημιουργία Dataset
Τους τελευταίους μήνες η ομαδα glossAPI επικεντρώθηκε στη δημιουργία 5 dataset που περιέχουν κείμενα λογοτεχνικά και μη σε όλες τις γλωσσικές ποικιλίες της ελληνικής γλώσσας. Μέσα από διαδοχικές δοκιμές έγινε ο καθαρισμός των δεδομένων (preprocessing) ο οποίος υλοποιήθηκε σε δύο φάσεις: στον χονδρικό καθαρισμό και στον ποιοτικο καθαρισμό. Πιο αναλυτικά:
- scraping
- Κανόνες καθαρισμού χονδρικού
- Κανόνες καθαρισμού λεπτού
- διάγραμμα ροής
- Εφαρμογή του φίλτρου BERT για την αυτόματη επισημειωση της ποικιλίας
- Παραδοτέο στο Hugging face https://huggingface.co/glossAPI
Διαγραμματική απεικόνιση της μεθόδου του καθαρισμού των δεδομένων μας
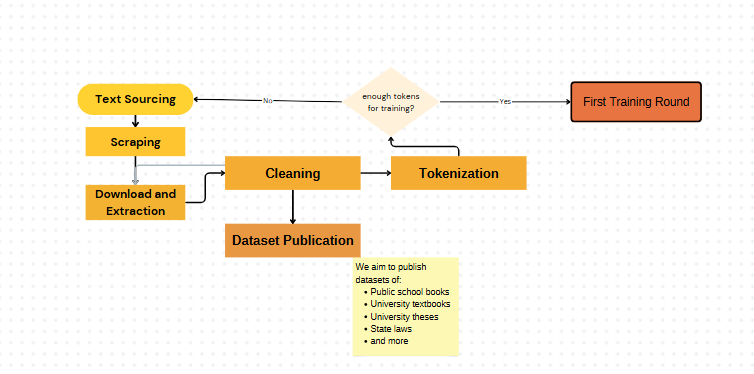
1ο dataset περιέχει 95K προτάσεις 3 ποικιλιών της ελληνικής γλώσσας (Καθαρεύουσα, Δημοτική, Κοινή Νέα Ελληνική). Για τη δημιουργία του αξιοποιήθηκαν οι πηγές: Europarl , GlobalVoices , HNC , CCMatrix, Wikipedia, Wikimatrix . Η επισημείωση αυτών έγινε αυτόματα από το μοντέλο που εκπαίδευσε η ομάδα glossAPI (https://huggingface.co/glossAPI/Kategoriopoiitis_Ellinikon_Poikilion ) .
2o dataset περιέχει 214 κείμενα σε όλες τις ποικιλίες της ελληνικής γλώσσας (Αρχαία, Καθαρεύουσα, Δημοτική, ΚΝΕ). Τα κείμενα αντλήθηκαν από το Project Gutenberg και αφορούν έργα της ελληνικής γραμματείας. Η επισημείωση αυτών έγινε αυτόματα από το μοντέλο που εκπαίδευσε η ομάδα glossAPI (https://huggingface.co/glossAPI/Kategoriopoiitis_Ellinikon_Poikilion ) .
Τα datasets “First1kGreek” και “Canonical-Greeklit” περιέχουν έργα γνωστά και λιγότερο γνωστά, χρονολογούμενα από την αρχαιότητα έως το 250 μ.Χ. και από την αρχαιότητα και τους λατινικούς χρόνους, αντίστοιχα. Περιέχουν επίσης αναφορές στο λεξιλόγιο των κειμένων, μαζί με σχόλια και διευκρινίσεις (https://huggingface.co/datasets/glossAPI/First1kGreek ).
Το dataset “dimodis_logotexnia” περιλαμβάνει έργα της ελληνικής γλώσσας από τον 12ο έως και τον 18ο/19ο αιώνα. Αφορά κείμενα πολύ σημαντικά για τα ελληνικά γράμματα (κρητική λογοτεχνία, έπος, ιπποτικό μυθιστόρημα, Πτωχοπροδρομικά), ενώ παρατίθενται και διδακτικές προτάσεις για αυτά (https://huggingface.co/datasets/glossAPI/95k_deigma_ellinikis ).
Τέλος, δημιουργήθηκε dataset με όλα τα ελληνικά σχολικά βιβλία της πρωτοβάθμιας και δευτεροβάθμιας εκπαίδευσης. Αποτελείται από 122 κείμενα, έχοντας αφαιρέσει τα ξενόγλωσσα βιβλία (αγγλικά, γερμανικά, γαλλικά), τα τετράδια εργασιών και τα βιβλία του καθηγητή ( https://huggingface.co/datasets/glossAPI/Sxolika_vivlia). Ο κώδικας καθαρισμου διατίθεται ελεύθερα στο github του glossAPI (https://github.com/eellak/glossAPI)
Συνάντηση και συνεργασία με IBM
Έχουμε αποκτήσει πρόσβαση σε μια Nvidia L4 απο το cloud της IBM για τις ανάγκες της κοινότητας. Τους παρουσιάσαμε το γενικό πλαίσιο της εργασίας μας και τους στόχους μας για ένα ανοιχτό, Ελληνικό LLM.
Η ομάδα Deep Search μέσα στην εταιρεία τους έχει αναπτύξει το καλύτερο, ανοιχτό εργαλείο για εξαγωγή κειμένου από PDF κ.α. αρχεία: Docling. Αυτό διευκολύνει πολύ το έργο μας καθώς στο έργο του καθαρισμού ένα από τα βασικά προβλήματα είναι τα μη συστηματικά παράγωγα της διαδικασίας εξαγωγής.
Μεγάλωσε η ομάδα μας
Έχουμε ένα νέο μέλος, που εργάζεται καθημερινά σε εθελοντική βάση, τον Νίκο Βίδρα. Ο Νίκος είναι απόφοιτος της σχολής Πληροφορικής του ΕΚΠΑ. Έχουμε οργανωθεί σε ένα νέο σχήμα δύο ζευγαριών: προγραμματιστή – γλωσσολόγου. Ο Νίκος, με την Ιωάννα Μουρά,παρήγαγε το πρώτο του καθαρισμένο σύνολο δεδομένων.
Επίσης αυτή τη βδομάδα είχαμε μια νέα άφιξη, τη Βάνα Αρχοντή, ειδικό στις γλωσσικές τεχνολογίες. Η Βάνα θα συνεργάζεται κυρίως ασύγχρονα με την ομάδα μας σε θέματα αυτόματης επισημείωσης και prompt engineering.
Στοχοθεσία
Έχουμε ως στόχο να μαζέψουμε δεδομένα σε δύο διαστάσεις. Η μία καλύπτει όλο το χρονικό φάσμα της Ελληνικής γλώσσας: Ομηρική, Κλασική, Ελληνιστική κοινή, Μεσαιωνική κλπ μέχρι τη σύγχρονη καθομιλουμένη. Η δεύτερη αντιστοιχεί στη ποικιλία των χρήσεων της Ελληνικής, ειδικά όπως αντικατοπτρίζεται στις επαγγελματικές, ακαδημαϊκές και ειδάλλως διανοητικές ασχολίες των Ελλήνων σήμερα.
Το πρώτο GPT εκπαιδεύτηκε με 8GB κειμένου, ενώ το δεύτερο με 40GB. Η διαδικασία εκκαθάρισης δεδομένων είναι χρονοβόρα. Μέσος χρόνος καθαρισμού μιας πηγής βιβλίων είναι 3 εβδομάδες από μια ομάδα ενός γλωσσολόγου και ενός προγραμματιστή, ενώ ο χρόνος καθαρισμού μιας πηγής σε καλά οργανωμένο HTML ή XML είναι περίπου μία εβδομάδα. Στόχος μας είναι να τροποποιούμε τα εργαλεία που χρησιμοποιούμε και τη ροή εργασίας ενώ παράλληλα να μειώνεται ο χρόνος επεξεργασίας τους. Ενδεχομένως να έχουμε και καλά αποτελέσματα με τη μετεκπαίδευση ενός γλωσσικού μοντέλου πάνω στα δεδομένα μας πριν και μετά το καθαρισμό, ώστε να καθαρίζονται αυτόματα. Η εργασία της Βάνας εμπίπτει στην αυτοματοποίηση του καθαρισμού.
Επόμενα βήματα
Nέα Dataset στο Hugging Face
Μέσα από την άντληση από μια πληθώρα πηγών, που είναι καταγεγραμμένα με συστηματικό τρόπο στην βάση δεδομένων της ομάδας, η προαναφερόμενη ροή εργασίας επιτρέπει την αυτόματη ταξινόμησή τους σε ιστορικές περιόδους και γλωσσικές ποικιλίες.
- Sentiment Analysis / Summarization
Παράλληλα η ομάδα θα στραφεί στο πρόγραμμα Horizon Europe «AI4Deliberation» για την ανάπτυξη εργαλείων AI για Sentiment Analysis και Summarization. Η πρώτη προσέγγιση μας ήταν η συστηματική μελέτη της τρέχουσας βιβλιογραφίας σχετικα με τα Sentiment Analysis. Όσον αφορά στο Sentiment Analysis παρατηρήσαμε ότι η επιλογή Βαθιάς Μηχανικής μάθησης σε συνδυασμό με ημιεπιβλεπόμενη μηχανική μάθηση θα μπορούσε να είναι αποτελεσματική. Ένα εργαλείο χρήσιμο για την ανάλυση συναισθήματος, που βασίζεται σε ένα έτοιμο λεξικό και κανόνες, σχεδιασμένο ειδικά για να κατανοεί το συναίσθημα σε κείμενα, είναι το VADER.
- Περιοδικές συναντήσεις “AI HUBs”
Οι περιοδικές συναντήσεις “AI HUBS” έχουν ως στόχο την επιτελική ενημέρωση και πιθανές συνέργειες μεταξύ όλων των ερευνητικών ομάδων από πανεπιστήμια και ερευνητικά κέντρα που υλοποιούν δράσεις και έργα τεχνητής νοημοσύνης. Η πρωτοβουλία για τη σύνδεση Πανεπιστημίων και Ερευνητικών Κέντρων εντάσσεται στις προσπάθειες της ΕΕΛΛΑΚ να αναπτύξει ένα ελληνικό γλωσσικό μοντέλο ανοιχτού κώδικα το glossAPI. Στις προηγούμενες συναντήσεις συμμετειχαν στελέχη απο ΕΚ ΔΗΜΟΚΡΙΤΟΣ, ΕΔΥΤΕ, ΕΚΤ, ΕΜΠ, ΕΠΙΣΕ, Ινστιτούτο Επεξεργασίας του Λόγου, ΙΤΥΕ Διόφαντος, Μονάδα ΑΡΧΙΜΗΔΗΣ, ΟΠΑ, ΠΑΔΑ, Πανεπιστήμιο Πατρών, Χαροκόπειο. ➕Θέλετε να πάρετε μέρος σε μια επόμενη συνάντηση; Επικοινωνήστε με το admin@eellak.gr.
- Δημιουργία Κοινότητας
Στόχος της ομάδας είναι να δημιουργήσει ένα δίκτυο επικοινωνίας και ανταλλαγής τεχνογνωσίας στο πεδίο των Ψηφιακών Ανθρωπιστικών Σπουδών. Κάνοντας ανασκόπηση στη βιβλιογραφία και αναζήτηση πηγών γλωσσικών δεδομένων παρατηρήθηκε ότι έχει αναπτυχθεί η τάση από την ερευνητική κοινότητα για τη δημιουργία dataset που επικεντρώνονται στην ελληνική γλώσσα στην συγχρονική και διαχρονική διάστασή της. Αυτο το εγχείρημα ταιριάζει με τη στοχοθεσία της ομάδας glossAPI καθώς μακροπρόθεσμα φιλοδοξει στην αναπτυξη LLM και χρειάζεται μεγάλο όγκο γλωσσικών δεδομένων. Επίσης θα μας ενδιέφερε ώς ομάδα να πληροφορηθούμε περεταίρω για τις ανάγκες της κοινότητας και την αξιοποίηση των dataset. Μια τέτοια επικοινωνία θα μπορούσε να δημιουργήσει ωφέλιμες συνεργασίες για την ομάδα glossAPI και την ΕΕΛΛΑΚ εν γένει. ➕Θέλετε να πάρετε μέρος στις συζητήσεις για Νέα & Τεχνικά θέματα στο Matrix/Element; Επικοινωνήστε με το admin@eellak.gr με θέμα “Κοινότητα glossAPI”.
Εάν γνωρίζετε κάποιον που ενδιαφέρεται να λαμβάνει αυτό ενημερωτικό δελτίο μπορείτε να του προτείνετε να εγγραφεί στο https://newsletters.ellak.gr/.
- Νέα / Χρήσιμοι σύνδεσμοι
Δημοσίευση των Αποτελεσμάτων της Συμβουλευτικής Επιτροπής Τεχνητής Νοημοσύνης … https://foresight.gov.gr/deltia-typou/1551/dimosieysi-ton-apotelesmaton-tis-symvouleytikis-epitropis-texnitis-noimosynis-ypo-ton-prothypourgo/
- https://nvlm-project.github.io/
- https://www3.weforum.org/docs/WEF_Advancing_Data_Equity_2024.pdf
- https://tselai.com/meltemi-llamafile
- https://signalprocessingsociety.org/newsletter/2024/04/free-machine-learning-lecture-series-sps-resource-center
- https://videos.trom.tf/w/2wqkipt5BXFrJv24tEVPYV
- https://services.google.com/fh/files/misc/gemini-for-google-workspace-prompting-guide-101.pdf
- https://medium.com/data-policy/we-are-developing-ai-at-the-detriment-of-the-global-south-how-a-focus-on-responsible-data-re-use-1fd153104758
- https://europeanreviewofbooks.com/without-cause/?utm_source=facebook&fbclid=IwY2xjawF2cGhleHRuA2FlbQEwAAEd-ZiQDWVtiywSTnZgbNLD3FnutjjaAKuUuyviZhNNsD080u9MSEdLqZ0u_aem_4G1R-DfSNYLsiPUNxYQcuQ&utm_medium=paid&utm_id=120205680569020318&utm_content=120210981038960318&utm_term=120210981038970318&utm_campaign=120205680569020318
- https://academic.oup.com/pnasnexus/article/3/9/pgae400/7754871
- https://openexo.com/l/214444df
- https://www.kathimerini.gr/society/563280640/to-schedio-gia-elliniki-techniti-noimosyni/?utm_medium=Social&utm_source=Twitter#Echobox=1729435331-1
- https://far.ai/
- https://open.substack.com/pub/garymarcus/p/confirmed-llms-have-indeed-reached
- https://www.naftemporiki.gr/techscience/1815592/techniti-noimosyni-i-elliniki-protasi-gia-ta-ai-factories/
- https://digital-strategy.ec.europa.eu/en/news/commission-publishes-first-draft-general-purpose-artificial-intelligence-code-practice
- https://tinyurl.com/mtvxu2nm
- https://tvxs.gr/news/sci-tech/techniti-noimosyni-ereyna-ta-megala-glossika-montela-dyskoleyontai-na-katanoisoyn-ton-pragmatiko-kosmo/
- https://hai.stanford.edu/news/global-ai-power-rankings-stanford-hai-tool-ranks-36-countries-ai
- https://www.alfavita.gr/ekpaideysi/462878_o-faros-tis-tehnitis-noimosynis-synanta-ton-yperypologisti-daidalo-emp-dimokritos
- https://foresight.gov.gr/en/studies/A-Blueprint-for-Greece-s-AI-Transformation/
- https://www.aitoolreport.com/articles/anthropic-revolutionizing-ai-with-data-tool?utm_source=aitoolreport.beehiiv.com&utm_medium=newsletter&utm_campaign=anthropic-revolutionizing-ai-with-data-tool